

Unread架构介绍
原文出处:http://weibo.com/p/1001643880172431480781
作者:唐扬,@唐扬TY

未读提醒功能在各种社交平台服务中较为常见,在微博中这些功能由Unread服务来提供。看似简单的功能,当请求量级达到一定规模后,成本、性能、稳定性的平衡将是架构设计的重点。
大纲
一 微博中Unread服务业务场景
在以timeline为核心的微博业务中, 未读数场景出现的频率较高,它可以是这样的…
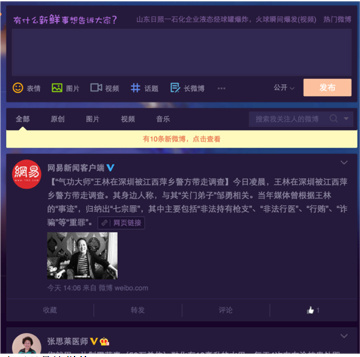
也可以是这样的…
二 从架构角度对各种业务场景的抽象
通过分析和比较这些未读场景,我们抽象了unread服务中设计到的三种主要操作:
1. incr:增加未读数
2. reset:未读数清零
3. get:获取未读数
我们发现unread服务中get操作是典型的无触发操作,即不需要用户执行任何操作都会对服务器造成请求。正是这个特点给unread服务带来如下问题:
1. 高并发:高峰期单一业务的qps达到10万+
2. 性能要求高:接口4个9的响应时间在10ms
为了解决上述问题,unread架构针对不同的业务场景设计了不同的方案,保证了服务的高性能、高可用和可扩展。本文主要针对三种典型的未读数场景介绍微博平台是如何设计解决方案的。
场景一. 一对一行为未读提醒场景
在这种场景下,用户的某一个操作只会影响一个用户的未读数字。典型的场景有:@未读提醒、评论未读提醒、赞评论提醒等等。
针对这种场景,我们采用最简单的解决方案:为每一个用户存储一份未读数字,如下图

在设计的实现中,由于存储容量可控,我们采用redis存储未读数。相比于通常使用的mysql+mc的存储解决方案,redis有以下的优势:
1. 存储一体化,避免了缓存和持久化存储之间一致性的问题
2. 快速恢复
这个设计方案主要基于如下的考虑:
1. 简单直观
2. 性能能够达到SLA,每次操作只需要访问一次资源
场景二. 全量打点场景
打点主要指微博官方客户端中的一些弱提醒功能,见下图中的红点
而全量打点指对全量用户都增加未读提醒红点。考虑到目前微博的用户量,如果采用第一种场景的方案,打点过程会存在很大的延迟。因此我们采用了基于tag的解决方案。
1. 存储公共的时间戳global
2. 每一个用户存储一个时间戳
3. 打点时,更新global时间戳为当前时间
4. 消点时,更新用户的时间戳为global时间戳
5. 如果用户时间戳小于global时间戳,则有点;否则没有点
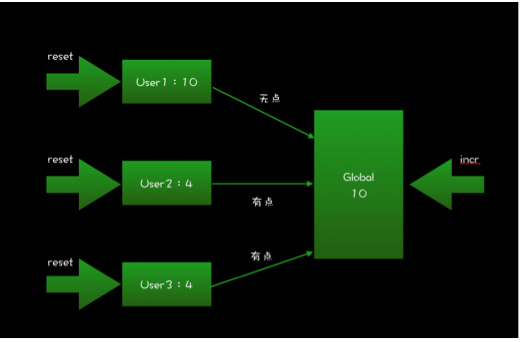
这个方案适用于用户间存在共享存储,且共享存储有限的场景。在这种场景下,我们为每一个用户存储一个tag用来记录用户在共享存储中的已读位置,这样就可以通过比较这个已读位置获得用户的未读数。
在实际的应用过程中,我们通常会使用本地缓存来解决访问共享存储的极端峰值。这种基于已读位置的解决方案虽然能很好的解决全量打点的问题,但是面对访问量最大的微博未读数场景却是无能为力,原因有二:
1. 用户的feed是无限的,不存在共享存储,全部存储下来的成本很高
2. 在高并发下获取未读数操作性能衰减严重
我们采用了下面这种方案来解决微博未读数问题。
场景三. 微博未读数场景
众所周知,微博未读数就是微博主feed未读数,当我关注的人发表一条微博,我的微博未读数提醒就会加一。
对于微博微博数场景,我们采用了基于snapshot的解决方案,具体如图所示: