

zookeeper
1.谈一谈你对zookeep的认识?
分布式环境下,数据通过网络传输,数据的修改和增加需要各个集群节点同步;
Zookeeper就能够做到,它是解决数据一致性工具,它能够在分布式环境下协调各数据资源,保证数据的一致性,可靠性。它能够保证同一个客户端的请求在zookeeper集群中是按照顺序操作,而且是原子性操作;并且无论连接那个客户端看到的数据都是一致的。
它是怎么做到的?
这就涉及到Zookeeper的ZAB协议、选举机制、数据模型、底层算法等
2.ZAB协议(原子消息广播协议)?
Zookeeper依赖zab协议来实现分布式数据一致性,基于该协议,zookeeper实现了一种主备模式的系统架构,使用Zab协议作为数据一致性的算法;
Zab协议:
是在Paxos算法的基础上改造而来的,支持崩溃恢复机制,Zookeeper使用单一的主进程leader,处理客户端所有的请求事物,zab协议保证Leader广播的变更序列被顺序的处理:一个状态被处理,那么它所依赖的状态也一定被处理;Zab支持崩溃恢复,保证leader进程崩溃的时候可以重新选举出新的leader来管理数据,保证数据的完整性一致性。
这就涉及到zookeeper的过半选举机制?
3.Zookeeper的选举机制?
Zookeeper中采用“过半选举”实现数据的一致性,可靠性。
1)同步机制
在zookeeper中所有的事物请求都由一个主服务器(leader)处理,Leader将客户端的请求转换为一个事物,分发给所有的follower;同时leader按照请求更改自己的数据,follower按照leader给他们维护的编号顺序同步Leader中的数据。
Leader等待follower反馈,将反馈结果标记在“同步列表”中,当有超过半数的follower反馈“同步完成”,leader再次向集群内的follower广播commint,向客户端反馈“同步成功”; leader的责任(读+写+广播),follower责任(读+同步+反馈);
总结:“同步机制-&两次广播,两次反馈”
2)启动选举机制
Zab协议存在三种状态,Looking、Following、Leading。
Zookeeper启动的时候所有的节点都处于looking状态,这时集群会相互发送id尝试选举出一个Leader,只要其中一个Looking票数过半,选举成功,它将状态切换为Leading状态,其它的Looking切换为following状态;
如果选举不成功,重新选,直到选举出leader为止,我们可以在配置文件中设置重新选举的时间,第一次集群启动,重新选举并不影响集群工作。默认情况下,按照节点号,选除1外的第一个基数节点当leader。
总结:“所有following都有机会,过半则成,不成在选,有默认”
3)Leader宕机选举机制!
当leader宕机后,集群中的每一个Follower都想当Leader,它们都有机会,又都没有机会。
所有的follower会相互发送ZXID,对比ZXID,选择携带数据最新的follower当leader;
具体流程:
每个follower都会携带(ZXID)向其它节点发送请求,选自己为leader的vote,等待回复;
Follower接收到的ZXID比自己新,更新自己的vote为持有数据最新的follower的选票,否则拒绝;
每个follower中维护着一个投票记录表,不断的更新自己的选票,当某个节点的选票过半,该节点晋升为leader,选举结束。
所有的follower跟着新的leader同步,旧eader重启后变为follower,和新leader同步。
总结:“选最新”
4)Follower宕机选举
follower和Leader之间通过“心跳检测”来感知对方存在状态,follower每隔一段时间向follower发送心跳报告,证明自己还活着。心跳机制通过RPC的一个接口类的一个方法来发; 当有过半的follower的没有发送心跳报告,Leader切换到Looking状态,活着的follower也随之切换到Looking状态,集群停止工作,开始新一轮的选举。
4.Zookeeper的数据模型是什么?
采用znode(节点树)来保存数据,znode内部可以保存数据,还可以挂载0至多个znode;
每一个节点都有唯一性,可以用来做统一的命名服务,其数据保存在内存中; Znode可以分为临时的,持久的,普通的,顺序的;
因此,它4种存储类型:普通临时,普通持久,顺序临时,顺序持久
创建节点的指令:
- creat /park01
- creat -e /park01
- creat -s /park01
- creat -e -s /park01
临时节点客户端断开后,节点删除;
5.Zookeeper的特点:
顺序一致性,原子性,单一视图,可靠性,伪实时性。
6.分布式环境下数据一致性算法?
2PC算法:
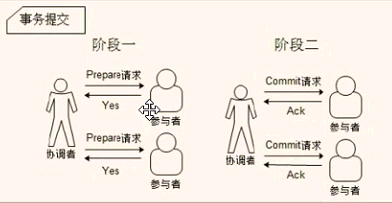
所有的参与者都成功事物才成功,原子性操作。
缺点:同步阻塞,单点故障,闹裂(一个集群中出现两个以上leader),太保守。
Paxos算法:
拜占庭将军问题-> 三支相隔遥远的军队一起打某个国家,分布式环境下达成协议, 信使传递消息,信使被收买怎么办? 信道不可靠解决不了这个问题。
Paxos算法采用过半机制,一半通过则协议达成,还支持角色替换,但是会产生活锁的问题,两个人一直让不开的问题。
ZAB算法: 在Paxos的基础上改进,支持崩溃恢复,就是选举产生活锁的时候,集群停止工作,重新选举。
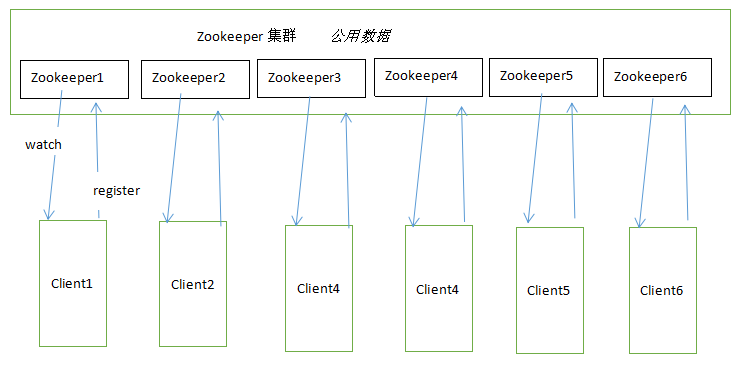
7.看图说话
8.Zookeeper的事物操作 ?
事物Zxid全局唯一,递增,zxid越大,事物越新,在选举的时候,可以用到。 选举id: 置文件中配置,事物Zxid选举不出来,用选举ID;
9.补充:
心跳机制时间,默认10秒,可以调整,集群环境不好,可以调整 原子广播端口:2888;选举端口自己配置:3888; 配置观察者模式指定观察者
10.图解——Zookeeper的选举 ?
原子广播:选举 和 写入操作时影响性能;
Observe观察者,服从投票结果,不参与投票,能提供性能。
例如:阿里Observe的应用,杭州leader和flower,每个和青岛observer

提供一个教材给大家学习
https://www.yiibai.com/zookeeper/zookeeper_api.html